Goldman Sachs SDE III Interview Questions
Table Of Contents
- What is the difference between a stack and a queue? Provide examples of their use cases.
- Write a program to find the missing number in an array of consecutive integers.
- What are the differences between breadth-first search (BFS) and depth-first search (DFS)?
- What is the difference between malloc() and calloc() in memory management?
- How does garbage collection work in Java, and what are the common types of garbage collectors?
- What are the key differences between a relational database and a NoSQL database?
- Design an efficient algorithm to find the longest increasing subsequence in an array.
- A critical service in your application fails during peak hours. How would you mitigate the impact and prevent future occurrences?
- You need to migrate a monolithic application to a microservices architecture. What are the key steps you would take?
Preparing for the Goldman Sachs SDE III Interview is no easy feat, but with the right guidance, you can approach it with confidence. In my experience, this interview is known for its rigorous assessment of both technical expertise and problem-solving abilities. You’ll face tough questions that test your mastery of data structures, algorithms, and system design. Expect coding challenges that require you to demonstrate your understanding of arrays, linked lists, trees, graphs, and dynamic programming. The interviewers will push you to think on your feet, optimize your solutions, and solve problems under tight time constraints. Additionally, they’ll assess your ability to communicate complex ideas and work through real-world scenarios, making behavioral questions a key part of the process.
In this guide, I’ll break down exactly what you need to prepare for the Goldman Sachs SDE III Interview. You’ll find a well-structured set of interview questions covering coding, system design, and behavioral aspects, along with step-by-step solutions and tips to help you succeed. By going through this content, I’ll help you understand the type of challenges you’ll face and how to tackle them effectively. Whether you’re brushing up on your technical skills or improving your interview strategy, this resource will equip you with everything needed to ace the interview and stand out as a top candidate.
1. What is the difference between a stack and a queue? Provide examples of their use cases.
A stack is a linear data structure that follows the LIFO (Last In, First Out) principle, meaning the last element added to the stack is the first one to be removed. Imagine a stack of plates where you can only add or remove plates from the top. Operations like push (add) and pop (remove) happen at one end, known as the top of the stack. A common use case for stacks is in function call management, where the last function called must finish execution before previous ones resume.
On the other hand, a queue is a linear data structure that operates on the FIFO (First In, First Out) principle, meaning the first element added is the first one to be removed. Think of a queue as a line at a grocery store, where people leave the queue in the order they joined. Queues are widely used in task scheduling, such as handling requests in a print queue or managing processes in an operating system. The key distinction lies in how these data structures handle insertion and deletion, making them suitable for different scenarios.
2. Explain how a hash table works and its advantages over arrays.
A hash table is a data structure that maps keys to values using a hash function. This function converts the key into a hash code, which determines where the value is stored in the table. Hash tables allow for constant-time complexity (O(1)) for lookup, insertion, and deletion, assuming a good hash function is in place. They are particularly effective for use cases like dictionaries or caches, where quick access to data is essential.
Compared to arrays, hash tables offer more flexibility in storing data with arbitrary keys instead of numerical indices. However, arrays have fixed sizes, while hash tables dynamically resize themselves to handle collisions (when two keys map to the same hash code). This is managed using techniques like chaining (storing multiple values at one hash index) or open addressing (finding the next available slot). While hash tables are efficient, poor hash functions can lead to performance issues, making their design crucial in practical applications.
3. Write a program to find the missing number in an array of consecutive integers.
To find the missing number in an array of consecutive integers, I’d use the formula for the sum of the first n natural numbers:
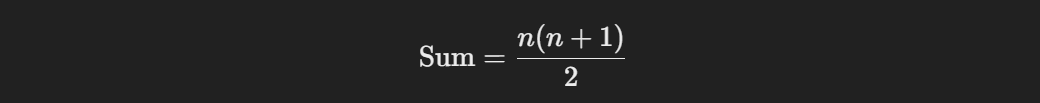
Subtracting the sum of elements in the array from this calculated total gives the missing number. Here’s a simple program in Python:
def find_missing_number(arr):
n = len(arr) + 1 # Total numbers including the missing one
total_sum = n * (n + 1) // 2 # Sum of first n natural numbers
array_sum = sum(arr) # Sum of array elements
return total_sum - array_sum
# Example usage
arr = [1, 2, 4, 5, 6]
print("Missing number:", find_missing_number(arr))In this example, the array [1, 2, 4, 5, 6] is missing the number 3. The program calculates the total sum for n=6, subtracts the array sum, and returns 3 as the missing number. This approach is efficient, with O(n) time complexity, and avoids sorting or additional space usage, making it practical for large datasets.
4. What are the differences between breadth-first search (BFS) and depth-first search (DFS)?
Breadth-First Search (BFS) explores nodes level by level, starting from the root or a starting node, and visiting all its neighbors before moving to the next level. This approach uses a queue to keep track of the nodes to visit next. BFS is ideal for scenarios like finding the shortest path in an unweighted graph or solving puzzles like the shortest moves in a maze. It ensures that the shortest path is found first due to its level-order traversal.
Depth-First Search (DFS), on the other hand, dives deep into one branch of the graph before backtracking to explore other branches. It uses a stack (or recursion) to manage its nodes. DFS is often used for applications like detecting cycles in a graph, topological sorting, or pathfinding in a maze where all paths need exploration. Unlike BFS, DFS may not always find the shortest path because it explores depth before breadth.
Here’s a simple comparison:
- BFS: Uses a queue, explores level-by-level, and finds the shortest path in unweighted graphs.
- DFS: Uses a stack (or recursion), explores deeply first, and works well for full exploration tasks.
5. Explain the concept of dynamic programming with a simple example.
Dynamic programming (DP) is a method for solving complex problems by breaking them down into smaller overlapping subproblems. It involves solving each subproblem once and storing the results to avoid redundant computations. This approach is particularly useful in optimization problems where recursion alone leads to excessive repeated calculations.
A classic example is the Fibonacci sequence. Without DP, calculating Fibonacci numbers using recursion leads to exponential time complexity due to repeated calls. By storing results of already calculated Fibonacci numbers in an array (memoization), we reduce the complexity to O(n). Here’s how it works:
def fibonacci(n):
dp = [0] * (n + 1) # Array to store Fibonacci numbers
dp[1] = 1 # Base case
for i in range(2, n + 1):
dp[i] = dp[i - 1] + dp[i - 2] # Recurrence relation
return dp[n]
# Example usage
print("Fibonacci(10):", fibonacci(10))In this example, the function calculates the 10th Fibonacci number efficiently by leveraging previously computed values. DP is a game-changer for problems like knapsack, longest common subsequence, and matrix chain multiplication, making them feasible to solve within practical time limits.
6. What is the difference between malloc() and calloc() in memory management?
The malloc() function in C is used to allocate a block of memory of a specified size dynamically. It does not initialize the allocated memory, meaning the memory contains garbage values by default. For example, if you allocate memory for an array using malloc(), you must explicitly initialize each element before use. The syntax for malloc() is:
void* malloc(size_t size); On the other hand, calloc() not only allocates memory but also initializes it to zero. It is particularly useful when you want to ensure the allocated memory starts with a clean slate. The syntax for calloc() is:
void* calloc(size_t num, size_t size); The primary difference lies in initialization—malloc() does not initialize memory, while calloc() does, making the latter safer to use in some scenarios where uninitialized values could cause issues.
7. How does garbage collection work in Java, and what are the common types of garbage collectors?
Garbage collection (GC) in Java is an automatic process that identifies and removes objects no longer in use, freeing up memory for other objects. The garbage collector works by tracking object references and reclaiming memory occupied by unreachable objects. This eliminates the need for manual memory management and reduces memory leaks.
Java offers several types of garbage collectors, each suited for different workloads:
- Serial Garbage Collector: Uses a single thread and is suitable for applications with small data sets.
- Parallel Garbage Collector: Uses multiple threads for garbage collection, designed for high-throughput applications.
- CMS (Concurrent Mark-Sweep) Collector: Reduces application pause times by performing most garbage collection work concurrently with the application.
- G1 (Garbage First) Collector: Divides the heap into regions and prioritizes garbage collection in regions with the most garbage, balancing pause times and throughput.
Garbage collection ensures efficient memory management, but understanding how different collectors work helps optimize performance based on specific application needs.
8. Write a function to reverse a linked list.
Reversing a linked list involves reordering the next pointers of each node so that the last node becomes the head. Here’s an iterative implementation in Python:
class Node:
def __init__(self, data):
self.data = data
self.next = None
def reverse_linked_list(head):
prev = None
current = head
while current:
next_node = current.next # Store the next node
current.next = prev # Reverse the pointer
prev = current # Move prev to current
current = next_node # Move current to next
return prev # New head
# Example usage
head = Node(1)
head.next = Node(2)
head.next.next = Node(3)
reversed_head = reverse_linked_list(head) In this example, the function iterates through the list, reversing the direction of the next pointer for each node. By the end of the loop, prev points to the new head of the reversed list. This approach ensures O(n) time complexity and requires no additional space beyond a few pointers.
9. What are the key differences between a relational database and a NoSQL database?
A relational database (RDBMS) organizes data in structured tables with predefined schemas. Relationships between data are maintained through keys (primary and foreign). Examples of relational databases include MySQL, PostgreSQL, and SQL Server. They excel in use cases requiring structured data, strict integrity, and complex queries using SQL.
In contrast, NoSQL databases provide more flexibility by storing data in various formats such as documents, key-value pairs, columns, or graphs. They are schema-less, allowing for dynamic and unstructured data. Examples include MongoDB, Cassandra, and Neo4j. NoSQL databases are ideal for applications requiring scalability, such as real-time analytics, large-scale distributed systems, and unstructured data storage.
Here are the key differences:
- Data Structure: RDBMS uses tables; NoSQL uses flexible formats.
- Scalability: RDBMS scales vertically; NoSQL scales horizontally.
- Schema: RDBMS requires predefined schema; NoSQL is schema-less.
- Query Language: RDBMS uses SQL; NoSQL uses various query mechanisms.
Understanding these differences helps in selecting the right database for specific application needs.
10. Explain the concept of load balancing and its importance in distributed systems.
Load balancing is the process of distributing incoming network traffic across multiple servers to ensure no single server becomes overwhelmed. By balancing the load, it ensures high availability, scalability, and optimal resource utilization. A load balancer sits between the client and the servers, directing traffic based on predefined algorithms like round robin, least connections, or IP hash.
In distributed systems, load balancing is crucial for maintaining system reliability and performance. Without it, traffic spikes can overload individual servers, leading to crashes or slowdowns. Load balancers also help handle server failures by rerouting traffic to healthy servers, ensuring seamless user experience.
Modern load balancers, such as NGINX and HAProxy, often integrate additional features like SSL termination, caching, and real-time traffic monitoring, further enhancing distributed system performance. Effective load balancing is essential for businesses operating at scale, supporting millions of users.
Advanced Questions
11. How would you optimize a SQL query that performs poorly on large datasets?
To optimize a SQL query for large datasets, the first step is to analyze the query using tools like EXPLAIN or EXPLAIN PLAN. These tools provide insights into how the database executes the query, such as table scans, joins, and indexing. One key optimization is to ensure that indexes are used effectively. For instance, creating a composite index on columns frequently used in WHERE, GROUP BY, or ORDER BY clauses can drastically improve performance.
Another approach is to optimize the query itself by minimizing the number of rows processed. Use subqueries or CTEs to reduce complexity, and avoid using SELECT *, which fetches all columns unnecessarily. Instead, retrieve only the required columns. Additionally, denormalizing data in read-heavy scenarios or partitioning large tables into smaller, manageable chunks can also improve performance. By combining these techniques, you can ensure efficient query execution even for large datasets.
12. Explain the CAP theorem in distributed systems and its implications for database design.
The CAP theorem states that in a distributed system, it is impossible to simultaneously guarantee Consistency, Availability, and Partition Tolerance. You can achieve only two out of these three properties:
- Consistency ensures all nodes return the same data at any given time.
- Availability ensures every request receives a response, even if some nodes fail.
- Partition Tolerance ensures the system continues to operate despite network partitions.
For example, relational databases like MySQL prioritize consistency and availability, making them unsuitable for scenarios requiring high partition tolerance. In contrast, NoSQL databases like Cassandra focus on availability and partition tolerance, often relaxing consistency through eventual consistency models. Understanding CAP helps in choosing the right trade-offs for distributed system design, ensuring optimal performance based on application requirements.
13. Design an efficient algorithm to find the longest increasing subsequence in an array.
To find the longest increasing subsequence (LIS) in an array, a common approach is to use dynamic programming with binary search for efficiency. The algorithm maintains a list where each element represents the smallest possible value of the last element in an increasing subsequence of a given length. Here’s the Python code:
def longest_increasing_subsequence(arr):
from bisect import bisect_left
lis = []
for num in arr:
pos = bisect_left(lis, num)
if pos == len(lis):
lis.append(num)
else:
lis[pos] = num
return len(lis)
# Example usage
arr = [10, 9, 2, 5, 3, 7, 101, 18]
print(longest_increasing_subsequence(arr)) # Output: 4 The algorithm iterates through the array, using binary search to find the appropriate position for each element. It achieves O(n log n) complexity, making it efficient for large arrays. By understanding this approach, you can apply similar optimization techniques to other sequence-related problems.
14. How do you handle circular dependencies in microservices architecture?
Circular dependencies in microservices architecture occur when two or more services depend on each other, creating a dependency loop that complicates deployment and maintenance. To resolve this, I first analyze the dependencies using tools like dependency graphs or distributed tracing. Breaking these cycles often involves identifying and refactoring the shared logic.
One effective approach is to introduce a mediator service that centralizes shared functionality, reducing direct dependencies between services. Alternatively, using asynchronous communication patterns, such as message queues (e.g., Kafka or RabbitMQ), decouples services while maintaining functionality. For instance, instead of directly calling another service, one service can publish an event to a queue, and the dependent service can consume the event asynchronously. These strategies ensure a scalable, maintainable microservices architecture.
15. Discuss the trade-offs between vertical scaling and horizontal scaling in system design.
Vertical scaling involves increasing the capacity of a single server by adding more resources, such as CPU, memory, or storage. This approach is simpler to implement as it requires minimal changes to the application. However, it has limitations, such as hardware constraints and cost inefficiency at scale. Additionally, a single point of failure remains a risk.
On the other hand, horizontal scaling adds more servers to a system, distributing the workload across multiple nodes. This approach provides better fault tolerance and scalability but requires more complex setup and management, including load balancing and distributed data management. The choice between vertical and horizontal scaling depends on the application’s needs: vertical scaling suits smaller, monolithic applications, while horizontal scaling is ideal for large-scale distributed systems. Understanding these trade-offs helps design robust, scalable systems that align with organizational goals.
Scenario-Based Questions
16. You are tasked with designing a system to handle millions of transactions per second. How would you approach it?
To handle millions of transactions per second, I would design a highly scalable, distributed system. First, I would focus on partitioning data across multiple nodes using techniques like consistent hashing to evenly distribute the load. This ensures no single server becomes a bottleneck. Additionally, I’d employ load balancers to distribute incoming requests dynamically across the system. Using asynchronous processing with message queues like Kafka or RabbitMQ allows for decoupling components and managing high traffic efficiently.
Next, I would use a combination of in-memory databases like Redis for caching frequently accessed data and NoSQL databases like Cassandra for write-heavy workloads. To ensure data integrity, I would implement distributed consensus algorithms like Paxos or Raft for critical operations. Regular stress testing and monitoring using tools like Prometheus and Grafana would help identify bottlenecks, allowing me to optimize the system further as demand grows.
Here’s a basic Kafka producer example in Python:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
# Sending a million transactions to a topic
for i in range(1_000_000):
transaction = f"transaction-{i}"
producer.send('transactions', value=transaction.encode('utf-8'))
producer.close() This approach ensures scalability by offloading processing to consumers. Additionally, caching systems like Redis can reduce the read burden on databases, and NoSQL databases like Cassandra are ideal for high write throughput.
17. A service in your microservices architecture is experiencing high latency. How would you debug and resolve this issue?
When faced with high latency in a microservice, my first step would be to identify the root cause. I would use distributed tracing tools like Jaeger or Zipkin to trace requests as they pass through the system, pinpointing where delays occur. Additionally, I would monitor metrics such as response times, CPU usage, memory, and network latency using tools like Prometheus.
Once I identify the issue, I’d address it based on its nature. If the service is overwhelmed, I might introduce rate limiting or scale it horizontally by adding more instances. If database queries are slow, I’d optimize them by indexing or using caching layers. For network-related issues, I’d check for misconfigurations or bottlenecks in the load balancer. Implementing retries with exponential backoff and circuit breakers can further help mitigate transient latencies and improve overall reliability.
To debug high latency, I would use distributed tracing tools like Jaeger. For example, tracing an HTTP request through services can pinpoint bottlenecks:
apiVersion: tracing.jaegertracing.io/v1
kind: Jaeger
metadata:
name: simple-jaeger
spec:
strategy: all-in-one With this setup, you can observe slow responses in logs or metrics. Suppose database queries cause latency; adding an index to a frequently queried field improves performance. For instance:
CREATE INDEX idx_user_email ON users(email); This SQL command optimizes email lookups, drastically reducing query time.
18. Your system experiences a sudden surge in traffic. How would you ensure it remains operational without downtime?
To handle a sudden surge in traffic, I would first ensure the system has auto-scaling capabilities. Using cloud platforms like AWS or Azure, I’d configure auto-scaling groups to automatically add instances as demand increases. A robust load balancer would distribute the traffic evenly across available resources, ensuring no single instance is overwhelmed.
Additionally, I’d implement rate limiting to prevent abuse and ensure fair usage. Caching frequently accessed data with in-memory stores like Redis can significantly reduce the load on backend services. For databases, I’d use read replicas to offload read-heavy operations. Monitoring traffic patterns in real time allows for proactive adjustments, ensuring the system remains responsive during traffic spikes. These measures together ensure seamless operation even under high demand.
Handling a traffic surge requires auto-scaling and efficient load balancing. Using AWS, for example, I’d define an auto-scaling policy:
{
"AutoScalingGroupName": "web-servers",
"MinSize": 2,
"MaxSize": 10,
"DesiredCapacity": 5
} This configuration automatically adjusts resources based on traffic. For read-heavy workloads, caching frequently accessed data in Redis significantly reduces the database load:
import redis
cache = redis.Redis(host='localhost', port=6379)
cache.set("popular_item", "12345")
# Fetch cached value
item = cache.get("popular_item") This approach ensures that most traffic is served from the cache, keeping backend systems responsive.
19. A critical service in your application fails during peak hours. How would you mitigate the impact and prevent future occurrences?
If a critical service fails during peak hours, my immediate priority would be to mitigate user impact. I’d use failover mechanisms to reroute requests to a backup instance or region. For microservices, implementing a circuit breaker pattern ensures failed services are temporarily bypassed, allowing the rest of the system to function.
Post-incident, I’d perform a root cause analysis to identify the failure’s origin. If it was due to resource exhaustion, I’d increase capacity or implement auto-scaling. For code-related issues, rigorous testing and canary deployments can help catch problems before widespread impact. Additionally, I’d enhance monitoring and alerting to detect anomalies early, ensuring proactive resolution and preventing similar failures in the future.
For example, with Netflix’s Hystrix, fallback logic can provide alternative responses:
@HystrixCommand(fallbackMethod = "fallbackResponse")
public String fetchServiceData() {
// Call to critical service
return restTemplate.getForObject("http://critical-service/data", String.class);
}
public String fallbackResponse() {
return "Default response due to service failure.";
} This ensures users get a degraded but functional response. To prevent recurrence, I’d conduct a post-mortem to identify root causes, improve monitoring, and enhance alert systems for early detection.
20. You need to migrate a monolithic application to a microservices architecture. What are the key steps you would take?
Migrating a monolithic application to microservices involves a phased approach to minimize risk. First, I would identify logical boundaries within the monolith, such as domain-specific functions (e.g., user management or payment processing). These would serve as the basis for independent services. Starting with low-risk modules ensures easier testing and validation.
Next, I’d implement communication between services using APIs or message queues for asynchronous tasks. To maintain data integrity, each service would have its own database, adhering to the database-per-service pattern. I’d set up monitoring tools like Prometheus and implement distributed tracing to ensure smooth operation. Gradually decomposing the monolith while maintaining functionality ensures a successful transition without disrupting users.
Using Spring Boot, a microservice for user management could look like this:
@RestController
@RequestMapping("/users")
public class UserController {
@GetMapping("/{id}")
public User getUser(@PathVariable String id) {
// Service call for user details
return userService.findUserById(id);
}
} Each microservice would have its own database to maintain loose coupling, following the database-per-service pattern. Communication between services could use RabbitMQ for decoupling, enabling asynchronous processing. This gradual modularization ensures the monolith evolves into a scalable and maintainable microservices system.

